Часто при попытке обработать данные с помощью различных функций языка Python, возникает ошибка вида:
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xd0 in position 0: ordinal not in range(12)
Ошибка как правило возникает при использовании символов, отличных от латиницы и никак не описана в документации к ArcGIS.
Что является причиной ошибки? Существуют так называемые кодировки символов – это таблицы соответствия определенных символов и числовых кодов (байтов), которые хранятся в памяти компьютера. Один и тот же символ в разных кодировках может быть представлен разными числами, которые хранятся в разных форматах (двоичные, десятичные и т.д.). По мере развития операционных систем и прикладных программ кодировок становилось все больше и преобразования между ними представляли большую проблему для программистов. То есть, для того, чтобы программы могли корректно считывать текстовые данные, они сначала должны узнать какая кодировка используется для хранения этой информации. Одним из вариантов решения проблемы является использование Юникода (Unicode) – стандарта и набора кодировок, который вмещает в себя практически все возможные и часто используемые символы. В том числе иероглифы, символы арабского, кириллического алфавита, технические символы и многое другое.
В языке программирования Python все строковые переменные хранятся и обрабатываются исключительно в Юникоде. Это означает, что любая строка, которая будет обрабатываться средствами Python, должна быть конвертирована в Юникод. Стандартные инструменты ArcGIS обычно делают это автоматически. Если слой создан и редактировался средствами ArcGIS, то любые символы в таблицах будут по умолчанию храниться в Юникоде. Если исходные данные импортированы из внешнего источника, то не исключено, что они хранятся в одной из стандартных кодировок.
В каких случаях могут возникать ошибки? Наиболее распространенные варианты: при запуске скриптов, использующих модуль arcpy, при использовании Python в калькуляторе поля ArcGIS, при использовании выражений на Python для создания подписей на карте.
Как избежать проблем? Если у вас встречаются строки на русском языке или с кириллическими символами, перекодируйте их в юникод с помощью встроенного метода decode(). В качестве параметра нужно указать название кодировки исходной строки. Например:
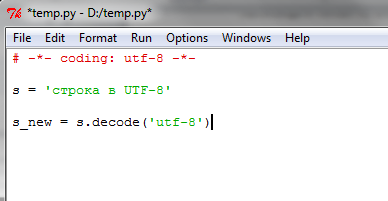
В данном случае переменной s присвоено строковое значение, содержащее символы в кодировке UTF-8. Далее это строковое значение (переменная) обрабатывается методом decode() и результат присваивается новой переменной s_new. Теперь строка закодирована с помощью Юникода, с которым работает Python, и дальнейшая ее обработка не будет вызывать ошибок типа UnicodeDecodeError.
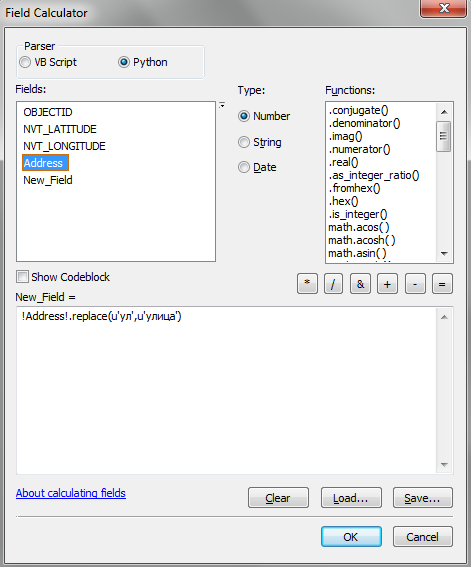
Тот же самый метод можно использовать в калькуляторе полей ArcGIS. К примеру, если вы попробуете произвести заменить сокращение “ул” на слово “улица” с помощью метода replace(), то обнаружите, что он перестает работать в случае использования русских символов.
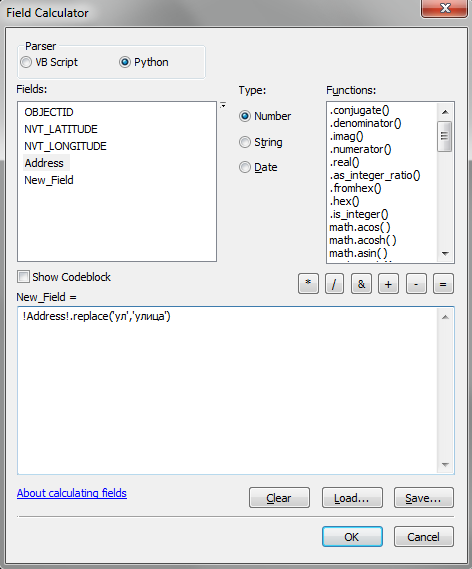
Происходит это потому, что в редакторе кода используется кодировка, которая определяется текущими региональными настройками Windows. Для русских символов это обычно кодировка ‘cp1251’. Для того, чтобы ошибка не возникала, нужно указать интерпретатору Python, что строки с кириллическими символами нужно перекодировать в юникод. Сделать это можно несколькими способами. Один способ, это использование метода decode(). Строка кода в таком случае будет выглядеть так:
!Address!.repalce(‘ул’.decode(‘cp1251’),’улица’.decode(‘cp1251’))
Кроме метода decode, есть метод unicode(). Для его использования вы можете указать перед текстовой строкой, что ее нужно конвертировать в Юникод. Краткая и наиболее удобная запись будет выглядеть так:
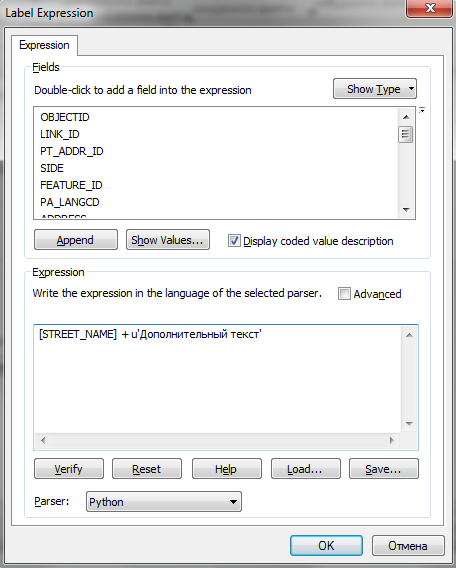
!Address!.repalce(u‘ул’,u’улица’)
То есть, перед строковым значением нужно поставить символ u. Такая форма записи является укороченным вариантом выражения unicode(‘строка’). Работающий вариант выражения в калькуляторе растров будет выглядеть следующим образом:
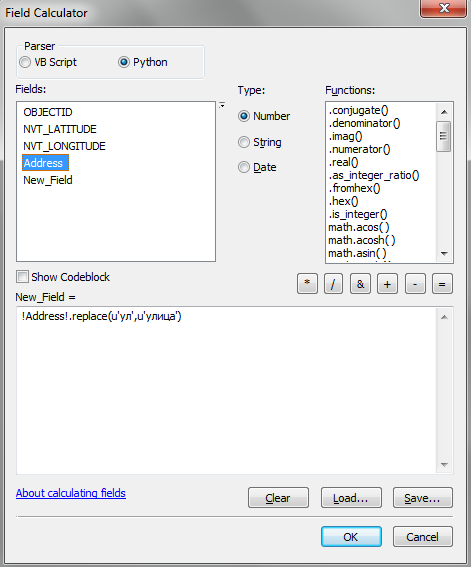
Проблемы с русскими символами возникают при использовании выражений на Python в инструментах создания подписей на карте. Решаются они аналогичным образом – с помощью указания интерпретатору кода, что данная строка должна быть перекодирована в Юникод.