Регрессия как инструмент предсказания значения параметра
Инструменты регрессионного анализа дают возможность найти математическую зависимость одного параметра от других параметров. Эта зависимость вычисляется с помощью так называемой обучающей выборки, т.е. набора данных в котором есть как известные значения переменной, которую мы хотим научиться предсказывать, так и значения входных переменных, которые будут использоваться для предсказания. После того, как регрессионая модель обучена, ее можно применить для предсказания значения нужной нам переменной на произвольном наборе входных данных.
Самым простым примером регрессии является линейная регрессия.
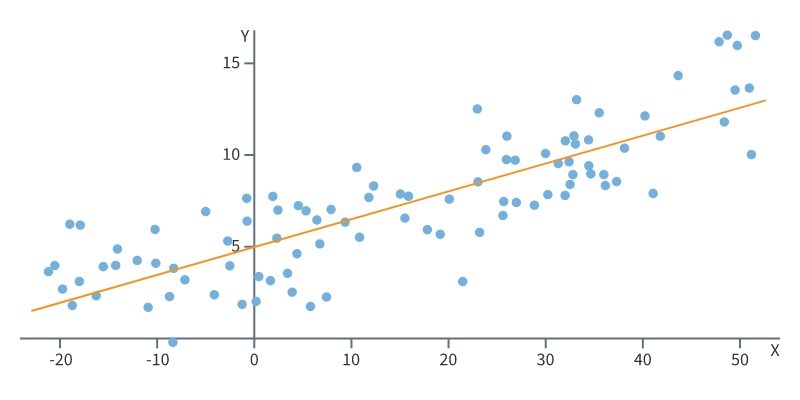
Предположим, есть набор данных с двумя атрибутивными полями — X и Y. Мы хотим найти зависимость между двумя этими атрибутами. Поле Y будет переменной, которую мы хотим предсказывать на основе значения переменной X. Линейная регрессия в данном случае, это функция Y = kX+b, где k и b — неизвестные параметры, которые нужно подобрать таким образом, чтобы сумма расстояний от каждой точки до линии была минимальной. Одним из методов подбора параметров k и b является «метод наименьших квадратов». Естественно, данная линейная фукнция (прямая) будет предсказывать значения переменной Y с некоторой ошибкой. Но если величина этих ошибок небольшая, сами ошибки распределены случайным образом, то это означает, что линейная функция сможет с достаточной точностью предсказать значение Y по входному значению X. Если ошибки слишком большие, распределение ошибок сильно отличается от слуайного, значит линейная функция не подходит для предсказания параметра Y и нужно искать другую функцию.
Что такое «машинное обучение»? Это алгоритмы, которые автоматически подбирают параметры функции (которая предсказывает значения) на основе данных из обучающей выборки.
Упражнения для знакомства с инструментами регресионного анализа в ArcGIS Pro
Пример 1. Создание модели оценки стоимости домов с помощью различных алгоритмов машинного обучения (регрессии).

Задача которая решается в упражнении: оценка стоимости дома на основе таких параметров как площадь, состояние дома, удаленность от центра, близость к побережью и т.д.
В упражнении используются инструменты:
- Generalized Linear Regression (Обобщенная линейная регрессия)
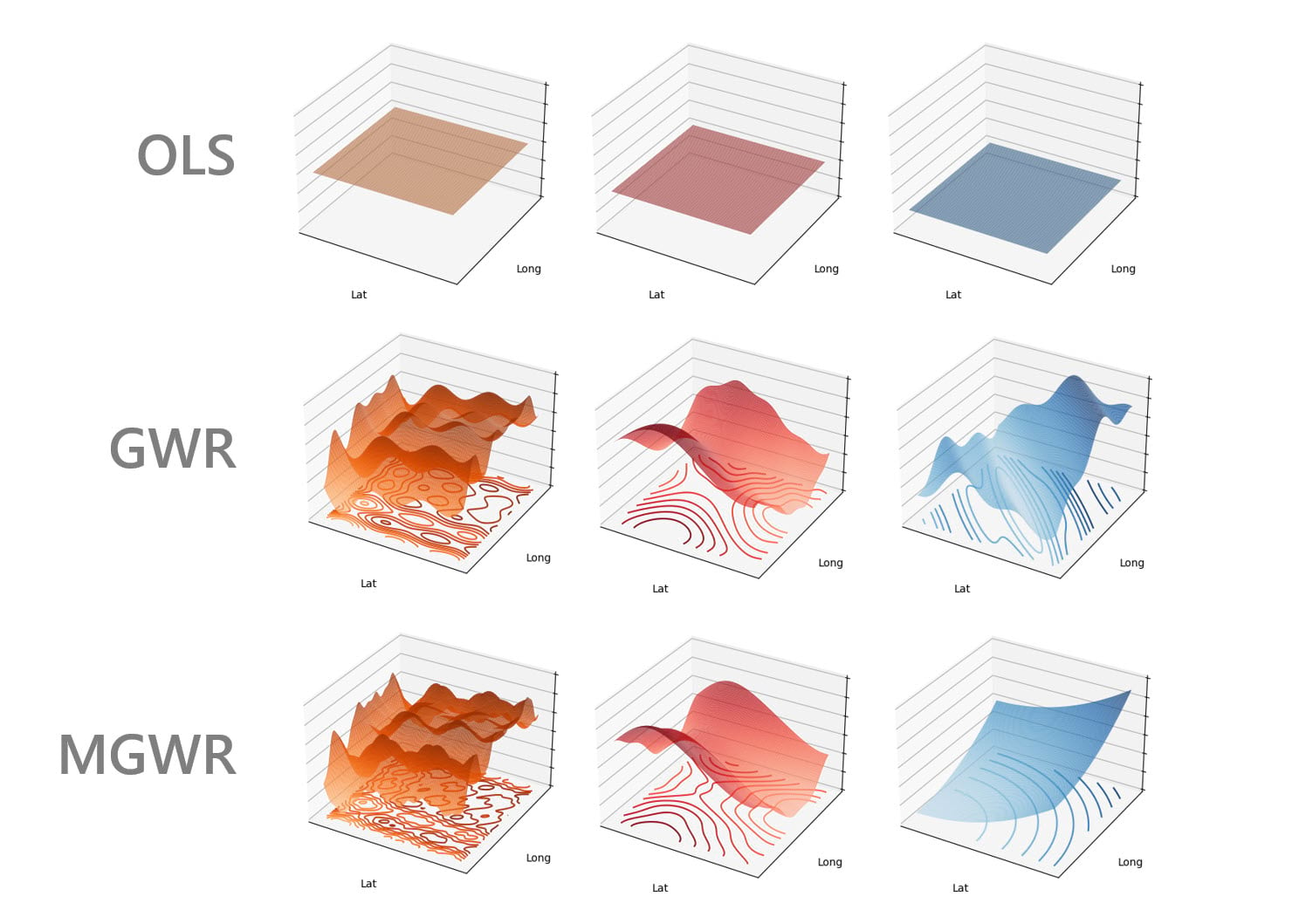
- Geographically Weighted Regression (Географически взвешенная регрессия)
- Forest-based and Boosted Classification and Regression (регрессия методом Random Forest и XGBoost)
Этом упражнении показана работа только с векторными данными. Если вы хотите использовать растровые данные, вы можете попробовать следующее упражнение.
Пример 2. Оценка биомассы растительности с помощью данных сенсора GEDI. Прогнозирование выполняется на основе растров, результатом прогноза является растр.

Задача которая решается в упражнении: оценка биомассы растительности на основе яркостей пикселей в каналах сцены Landsat, индекса NDVI, ЦМР, уклона поверности и экспозиции склона и т.д. В качестве опорны данных с информацией о биомассе растительности используюются измерения орбитального лазерного сенсора GEDI.
В упражнении используются инструменты:
Эти инструменты требуют наличия лицензии дополнительного модуля Image Analyst и ориентированы на работу только с растровыми данными.
Инструмент Forest-based and Boosted Classification and Regression умеет работать как с растровыми, так и с векторными данными одновременно, т.е. он более универсален, но если у вас все входные данные исключительно растровые и на выходе вы хотите получить растр с прогнозом, то инструмент Train Random Trees Regression Model является более предпочтительным вариантом, поскольку он оптимизирован именно для работы с растрами.
Пример 3. Прогнозирование ареала обитания кабанов в Калифорнии. Знакомство с алгоритмом MaxEnt.
Задача которая решается в упражнении: прогнозирование мест обитания кабанов на основе данных о климате, рельефе и ланшафте. В качестве опорных данных используются координаты мест, в которых были замечены кабаны. При этом нет никаких численных показателей количества кабанов, только сам факт того, что их заметили в этом районе. В этом упражнении используются алгоритмы машинного обучения, которые не являются регрессионными (поскольку у опорных данных есть только два значения: да или нет), но принципы построения предсказательной модели те же самые, что у всех моделей машинного обучения.
Алогритм MaxEnt умеет предсказывать вероятность присутствия явления или объекта на основе бинарной обучающей выборки. Обычно он используется экологами и биологами для предсказания мест обитания живых существ. Как правило трудно с достаточной точностью измерить вероятность присутствия того или иного вида в определенном районе, обычно есть только информация о том, замечен данный вид или нет, т.е. обучающая выборка представляет собой набор точек, в которых были когда либо замечены или найдены те или иные виды. На основе таких данных можно либо решить задачу классификации с двумы выходными классами (присуствует/отсутствует), либо воспользоваться алгоритмом MaxEnt и подсчитать вероятность присутствия вида.
Инструмент AutoML из набора инструментов GeoAI
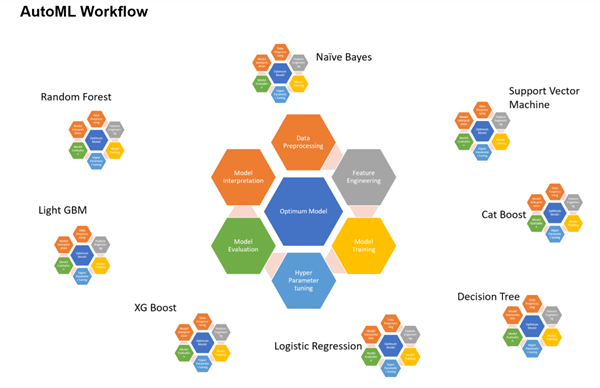
Для тех, кто хочет еще глубже погрузиться в тему машинного обучения. Поскольку задачи машинного обучения предполагают перебор разных алгоритмов с разными параметрами (и заранее неизвестно, какой алгоритм лучше подойдет для конкретной задачи), были придуманы инструменты автоматического перебора алгоритмов на основе одной и той же обучающей выборки. В ArcGIS Pro есть инструменты, которые позволяют решать эту задачу с помощью графического интерфейса, без написания кода:
Для работы с этими инструментами нужна лицензия ArcGIS Pro Advanced и установленные библиотеки Deep Learning. В качестве входных данных могут использоваться векторные и растровые слои. В качестве результата генерируются только векторные слои. Доступны следующие алгоритмы: Linear Regression, Decision Tree, CatBoost, Logistic Regression, XG Boost, Light GBM, Random Trees, SVM, Naive Bayes. Инструмент пропускает обучающую выборку через все эти алгоритмы и сравнивает полученные результаты с помощью набора метрик точности и производительности. Итогом работы инструмента является обученная модель с наилучшими показателями точности. А также таблица с значениями метрик точности и производительности для каждого алгоритма.
Важной особенностью инструмента является возможность использовать вложенные растры (attachments) в качестве дополнительного параметра. Например, для построения предсказательной модели стоимости недвижимости можно использовать не только атрибутивную информацию, но и фотографии объекта. В случае задачи предсказания стоимости недвижимости, этот параметр резко повышает точность модели. Поскольку на снимках хорошо видно реальное состояние объекта и оно существенно влияет на цену.