В этой статье я постараюсь показать некоторые не совсем очевидные моменты, которые надо учитывать про создании качественных обучающих выборок. Поможет в этом новый инструмент просмотра обучающих выборок, который появился в ArcGIS Pro 3.7.
Данные для примера возмьем из урока с сайта ArcGIS Learn.
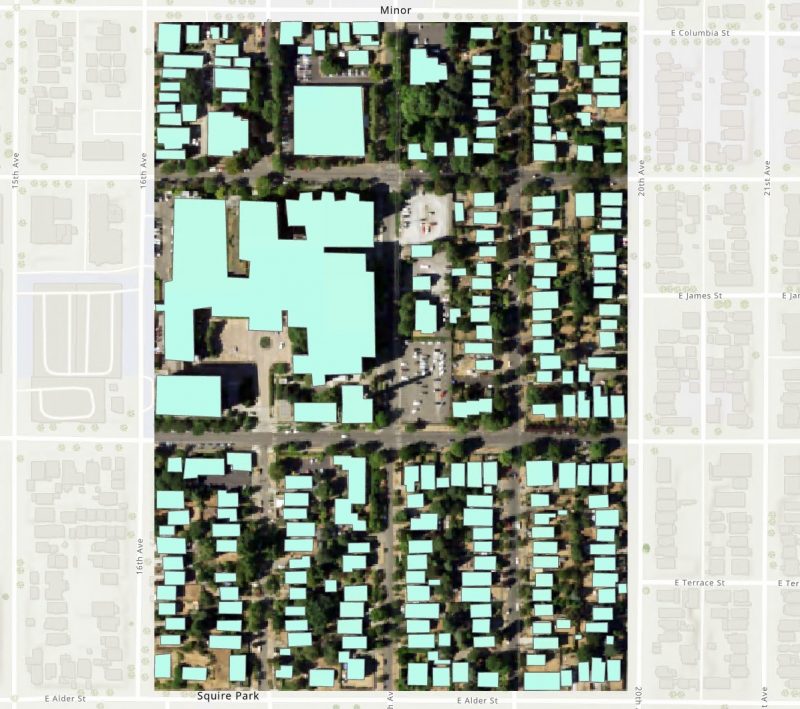
В архиве с данными для этого упражнения есть космический снимок с разрешением 1 метр. Мы будем дешифрировать контура строений на этом снимке с помощью нейросети на базе архитектуры Mask RCNN.
Сравнение двух обучающих выборок
Для начала подготовим обучающую выборку. Я сделал два варианта. Первый вариант — стандартная обучающая выборка в формате RCNN Masks без каких либо дополнительных параметров.
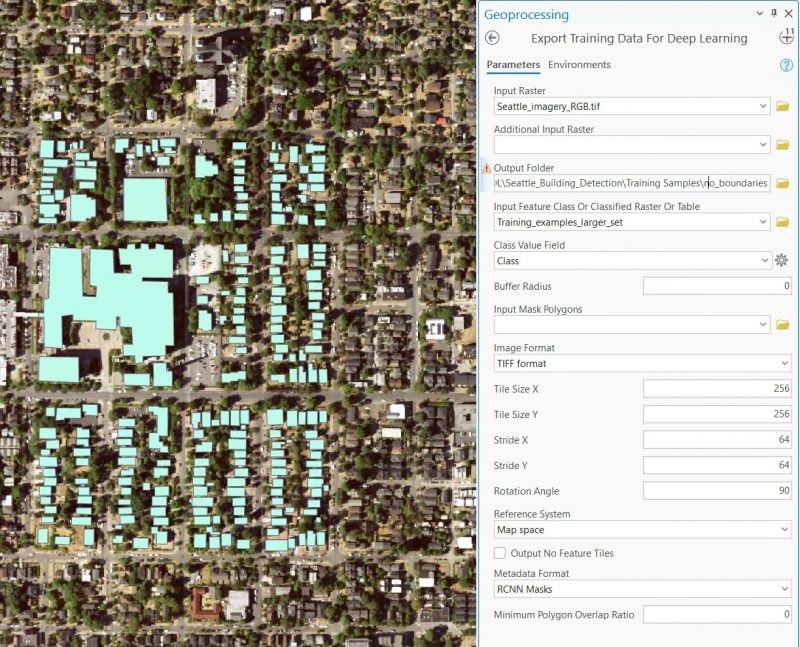
Для просмотра сгенерированной обучающей выборки воспользуемся новым инструментом Review labels and training data.

После того, как появится окно инструмента, нужно выбрать закладку Data и загрузить директорию с обучающей выборкой.
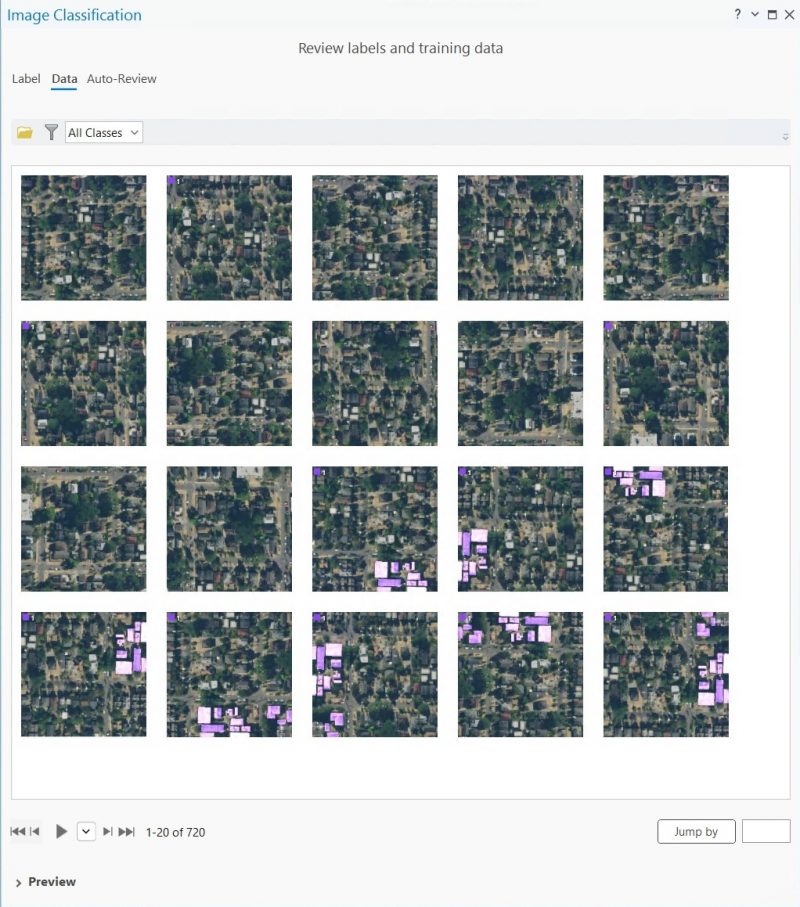
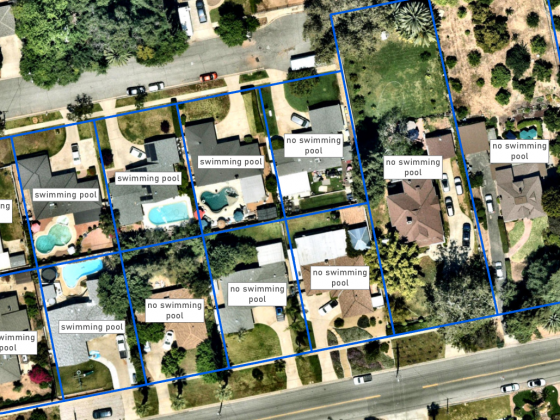
Что показывает инструмент? Где-то половина тайлов (из первых 20) не размечена вообще. Остальные размечены, но не полностью. Естественно, такая картина характерна не для всей выборки, а только для тайлов, которые расположены по краям.
Когда мы начнем обучать нейросеть, алгоритм обучения будет пытаться подобрать веса таким образом, чтобы неразмеченные строения попали в класс фона, несмотря на то, что они очень похожи на строения, которые размечены в обучающей выборке. Нейросеть будет пытаться найти признаки, которые отличают неразмеченные строения от размеченных. На самом деле этих признаков нет, но что-то будет найдено, записано в весах нейросети и в результате снизится точность классификации.
Почему так получилось? Потому что инструмент формирует тайлы с некоторым отступом от полигонов векторного слоя, на базе которого строится обучающая выборка. Если бы в этой небольшой буферной зоне не было строений, то все было бы нормально. Но в нашем случае там есть строения. Как сделать так, чтобы неразмеченные участки снимка не попадали в обучающую выборку?
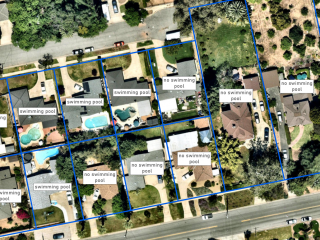
Сгенерируем второй вариант обучающей выборки, сохраним в другую директорию. В этот раз добавим в качествве дополнительного параметра полигональный слой с маской, который будет ограничивать территорию, для которой будет генерироваться обучающая выборка. Для маски нам нужна только геометрия, атрибуты этого слоя ни на что не влияют.
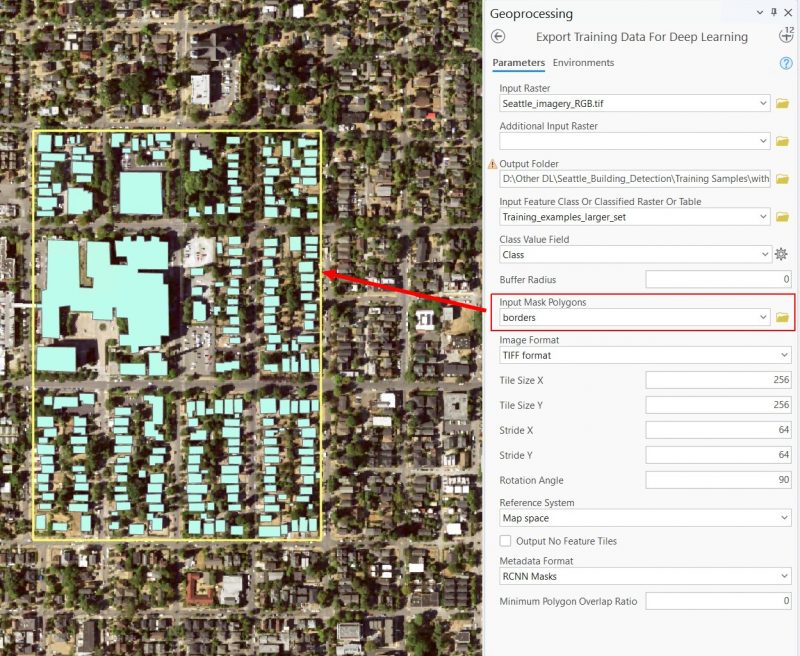
Все остальные параметры оставим такими же, как в первом варианте. Посмотрим на обучающую выборку с помощью инструмента Review labels and training data.
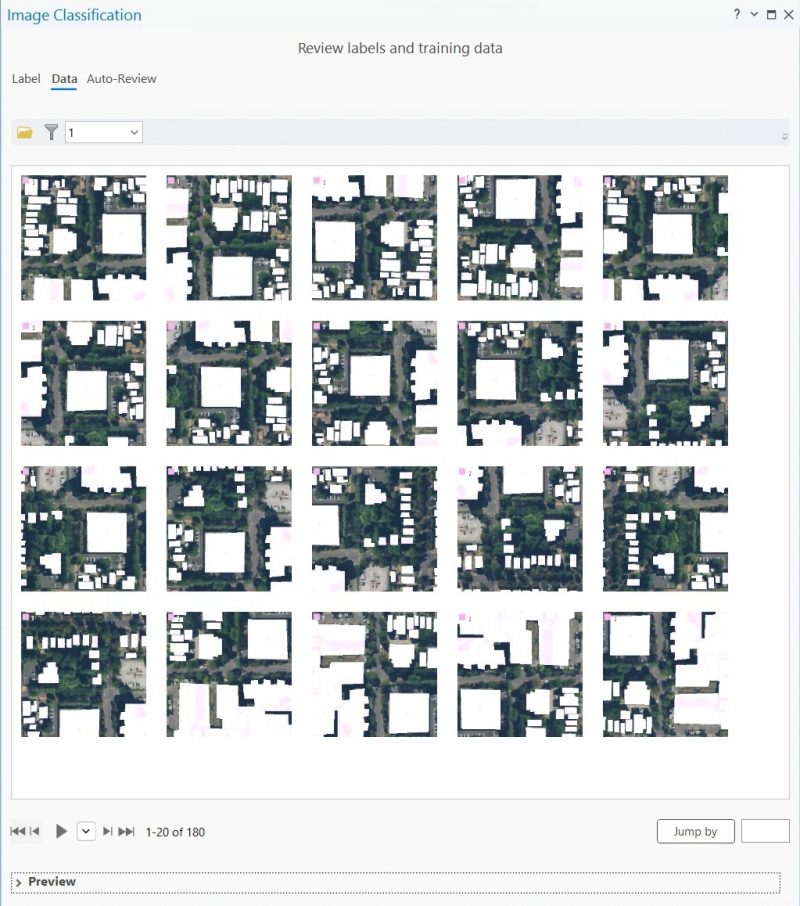
Теперь нет тайлов с неразмеченными строениями. В обучающую выборку попали только те участки снимка, которые лежат внутри полигонов маски.
Попробуем обучить две модели базе этих выборок и сравним результаты. Запускаем инструмент Train Deep Learning Model, 30 эпох обучения, все остальные параметры по умолчанию. Можно выключить Data Augmentation, но это не окажет существенного влияния на конечный результат.
После обучения двух моделей запустим выполним классификацию одной и той же территории. Параметры инструмента будут одинаковые.
Синим цветом в видеоролике показаны контура строений, сгенерированные на базе первой обучающей выборки (с пустыми и частично размеченными тайлами), желтым цветом — контура строений на базе второй обучающей выборки (без пустых тайлов). Второй вариант модели распознает где-то 90% зданий. Это довольно хороший результат с учетом очень небольшого набора обучающих данных и небольшого количества эпох обучения.
В упражнении, из которого взяты эти данные, производится процесс дообучения готовой модели с сайта Living Atlas. Там проблема, связанная с неразмеченными тайлами, решается с помощью вырезания исходного растра по экстенту обучающей выборки.
Этот вариант не всегда удобный, потому что может быть несколько участков с обучающими данными и тогда придется вырезать два фрагмента из растра, генерировать две и более директории с обучающими выборками и так далее. Проще использовать полигональную маску.
Когда нужно использовать полигональную маску?
Мысленно постройте небольшой буфер вокруг полигонов (линий, растров) на базе которых вы хотите сгенерировать обучающую выборку. Если в этот буфер попадают объекты, которые присутствуют хотя бы в одном классе обучающей выборки, значит нужен полигон с маской. После того, как вы сгенерировали обучающую выборку, проконтролируйте ее с помощью соответствующего инструмента ArcGIS Pro. Есть ли на ней неразмеченные объекты? Может быть, нужно дополнительно оцифровать объекты, добавить маску и т.д.
Заключение
Качественная обучающая выборка очень важна, если вы хотите получить точность классификации на уровне 90% и выше. Если у вас большая обучающая выборка, то эффекты неразмеченных тайлов по краям не так критичны, но все равно они могут снизить итоговую точность на 3-5%.
Для тех, кто хочет познакомиться с базовыми принципами обучения нейросетей в ArcGIS, рекомендую упражнение: Detect objects with a deep learning pretrained model. У большинства упражнений на сайте ArcGIS Learn есть перевод на русский, переключатель языка находится в правом верхнем углу страницы.
Статья в блоге Esri про новые инструменты GeoAI в ArcGIS Pro 3.7